RLSF: Reinforcement Learning via Symbolic Feedback
TLDR: We introduce RLSF, a novel fine-tuning paradigm that leverages symbolic reasoning tools to provide fine-grained feedback to LLMs, enabling precise alignment with domain-specific constraints and significantly improving performance on tasks with logical or mathematical requirements.
RLSF addresses key limitations of traditional reward signals by using symbolic reasoning tools such as:
1. Solvers and Provers: Provide formal verification and generate poly-sized certificates (e.g., proofs) that identify errors in model outputs.
2. Domain-Specific Tools: Chemistry simulators, compilers, and mathematical verification systems offer token-level guidance for precise error correction.
3. Symbolic Validators: Enable non-differentiable feedback without requiring gradient computation, making the approach broadly applicable across domains.
Unlike traditional RLHF approaches that rely on sparse, scalar rewards from human preferences or simple reward models, RLSF leverages poly-sized certificates generated by symbolic tools to provide token-level feedback. This enables more precise learning by pinpointing specific areas that need improvement rather than providing only binary pass/fail signals.
Framework Overview
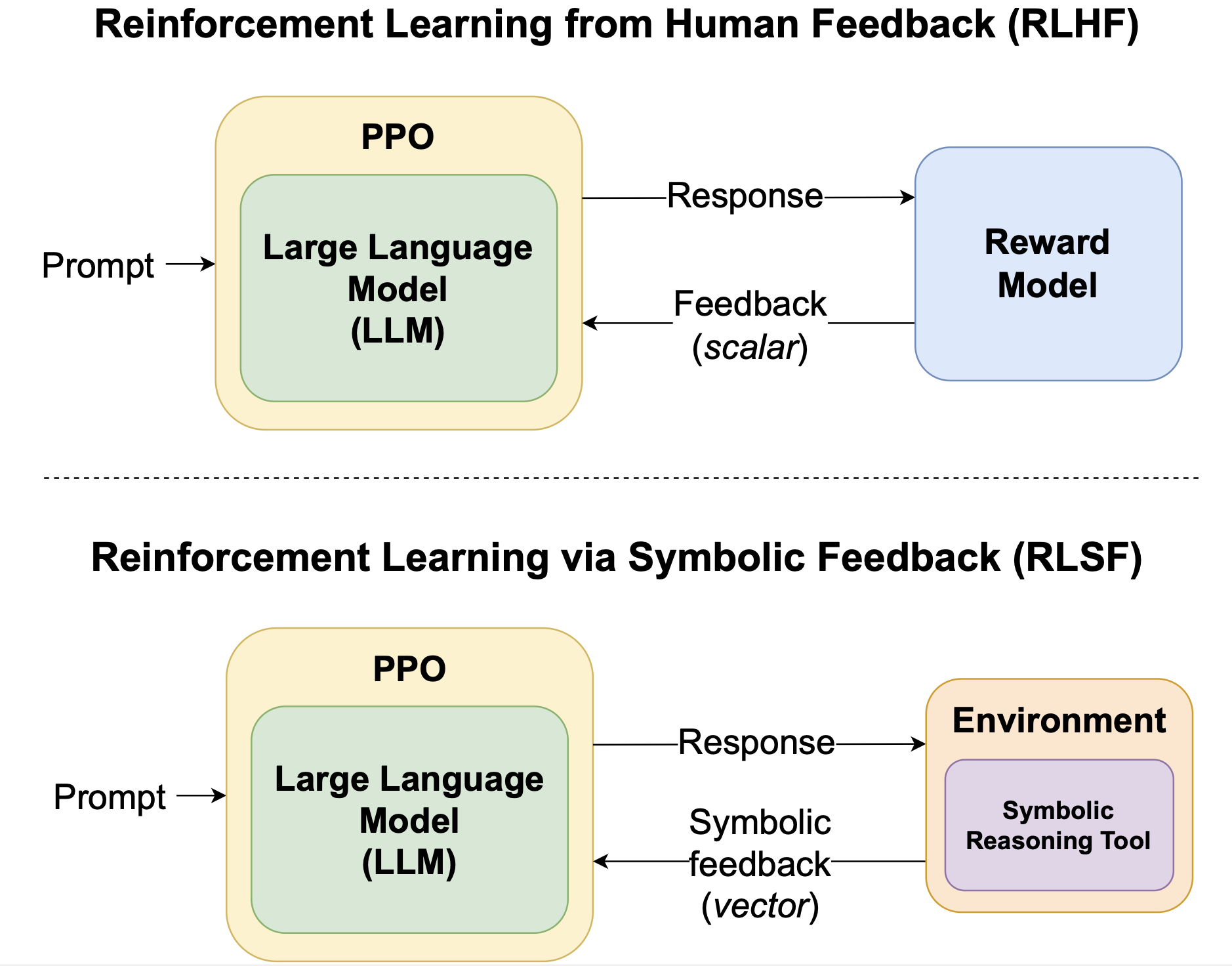
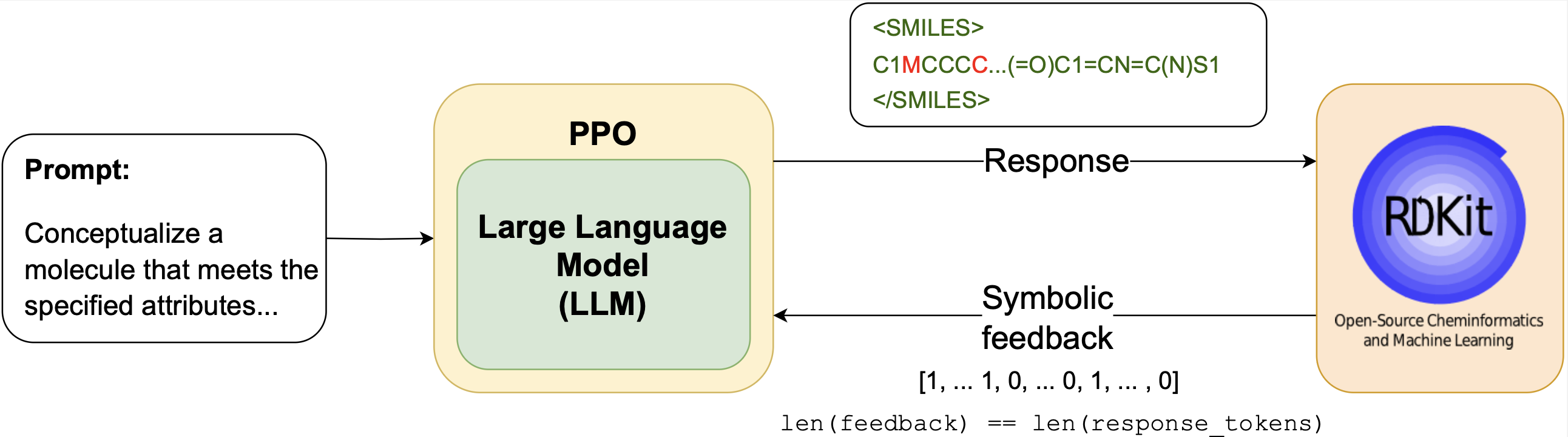
RLSF bridges the gap between symbolic reasoning and LLM fine-tuning by using external symbolic tools to generate rich feedback signals. Unlike traditional RLHF approaches that rely on human preferences or simple reward models, RLSF leverages the vast amount of symbolic domain knowledge available through reasoning tools.
The key innovation is the use of poly-sized certificates—formal proofs or verification results—that provide detailed information about where and why errors occur in model outputs. This enables token-level corrections and more efficient learning compared to sparse reward signals.
Our extensive evaluations across five different applications demonstrate that RLSF enables smaller LLMs to outperform much larger closed-source models, highlighting the effectiveness of symbolic feedback in guiding the learning process toward domain-specific constraints and logical consistency.